データレイクとデータウェアハウスの違いとは?
メリット・デメリット、その役割などを解説
注目されるビッグデータの蓄積・加工・分析
近年、ITやIoT、デジタル端末の発展・普及によって、企業はさまざまなデータの取得が可能となりました。そのデータ量は膨大かつ従来のような構造化された形式だけではなく、形式が定まらない非構造なデータも増えており、ビッグデータと言われています。
このビッグデータは、ビジネスの成長に向けた活用が期待されていますが、そのためにはデータの収集・蓄積・加工・分析を行うデータ分析基盤の構築が重要になります。
データ分析基盤に関しては、以下記事でご紹介しています。こちらもあわせてご覧ください。

基礎知識から構築する際の流れ、ポイントを解説
注意点として、システムがレガシーな環境な場合、そのデータ管理に多くの時間を取られてしまうことや、ビジネスニーズに柔軟に対応できないこと、さらにアジリティの欠如といった問題があります。
そのため、前提として、ビジネスデータの有効活用を行うためには、オンプレミスからクラウドへの移行やデータ分析基盤の構築を実施することが重要になることを押さえておきましょう。

組織における問題点と脱却する方法について解説!
以降では、データ分析基盤において重要なデータの蓄積を担う、「データレイク」と「データウェアハウス」についてご紹介します。
データレイクとは

データレイクとは、データの規模や性質に関わらず、すべてのデータを保管するリポジトリ(格納庫)のことです。非構造なデータもすべて未処理の形で保存を行うため、先述したビッグデータを収集・蓄積に適しています。
データレイクのメリット
メリットとしては以下3つが挙げられます。
- データの一元管理が可能
- データの保存に関するコストがかからない
- 高速でデータ共有ができる
大きなメリットは、あらゆる形式かつ膨大な量のデータを一元的に管理できることです。
また、データの格納時点ではデータの目的を決定したり構造化したりする必要がないため、保存に関するコストや時間をかけずにデータ処理ができ、スピーディなデータ共有が可能というメリットもあります。
データレイクのデメリット
デメリットとしては以下2つが挙げられます。
- データの取り扱い・管理が難しい
- 分析には手間と時間がかかる
データレイクは、あらゆるデータを生の状態で保存するため、専門的な知識がないとデータの取り扱いや管理などが困難です。また、保存されたデータの中から、欲しいデータを取り出すことに時間がかかるため、分析に多くの工数を要する点もデメリットです。
データウェアハウスとは

データウェアハウスとは、異なる種類のシステムから収集したビジネスデータを保管するリポジトリのことです。ここでのシステムとは、生産管理や販売管理といった「基幹系システム」や、MAツールやSFAツール・CRMツールといった「戦略系システム」などを指します。
あらゆるデータを未処理のまま保管するデータレイクとは異なり、データウェアハウスはビジネス上の観点にもとづきながら目的を設定し、その目的に見合うよう処理された構造化データを保管します。
データウェアハウスのメリット
メリットとしては以下3つが挙げられます。
- 分析しやすい形式で保存されているため検索性が高い
- 分析に向けたデータ処理が早い
- データに基づいた素早い意思決定が行える
データウェアハウスで保存されたデータは、分析が容易になるようフォーマットが整理されており、時系列といったサブジェクトごとの確認ができるようになっています。そのため検索性が高く、分析に向けたデータ処理もスムーズに行うことができます。
このような分析のしやすさから、的確かつスムーズな意思決定が可能です。
データウェアハウスのデメリット
デメリットとしては以下3つがあります。
- 柔軟な分析が行えない
- データの追加・更新・削除を行うことには向いていない
- 構築に一定の時間とコストが必要
データウェアハウスに保存されたデータは活用の目的が決められているため、定型的な分析しか行えず、柔軟な分析ができないことがデメリットです。また、データが構造化されているため、データの追加・更新・削除には向いていません。
さらに、膨大な量のデータを集約・整理するため、データウェアハウスの構築には一定の時間とコストを要します。
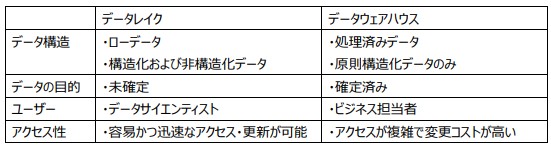
データレイクとデータウェアハウスの違い
データレイクは未処理のデータにすぐにアクセスできるため、データの前処理方法が分析手法によって変わるAI・機械学習を検討している際には構築すべきと言えます。
一方でデータウェアハウスは、現在導入しているシステムにて収集できるデータをもとに、経営・ビジネスに役立つデータ分析を行いたい場合に適しています。
このように役割が異なることから、多くの企業では、これらを統合したデータ分析基盤を構築しています。手順としては、まずビッグデータをデータレイクに収集・蓄積し、分析に必要となるデータをデータレイクから抽出し、加工後にデータウェアハウスへ保管するという運用を行っています。
また、実際にデータ分析基盤を運用する際は、以下4つの違いを押さえることも重要です。
● データ構造の違い
データレイクとデータウェアハウスでは、保管するデータの構造が異なります。データレイクはあらゆる形式のローデータを格納するのに対し、データウェアハウスは加工済みデータのみを格納します。また、未処理のローデータを保管するデータレイクは、ストレージ容量が大きくなりますが、データ活用の柔軟性は高いです。
● データの目的の違い
データレイクに保管されたデータは、目的を定まっていないものも多くあります。言い換えれば、データウェアハウスに比べ組織化やフィルタリングにはこだわらないということです。一方、データウェアハウスは特定の目的に合った処理済みデータを格納しており、消費するストレージ容量が小さい特徴もあります。
● ユーザーの違い
データレイクではデータを未処理の状態で保管するため、ローデータに慣れていないユーザーにとっては扱うハードルが高く、通常は専門知識やツールを持ったデータサイエンティストが扱います。一方、データウェアハウスには加工済みデータが格納され、チャートやテーブルなどで表示可能であるため、データサイエンティスト以外の一般的なビジネス担当者でも扱えます。
● アクセス性の違い
データレイクに保管されたデータは、構造化されていないためアクセスが容易であり、データの変更も迅速に行えます。一方、データウェアハウスはよりデータ処理や構造化が施されているため、データの解読は容易ですが、膨大なデータに対して前処理を実施するためストレージのコストが高くなります。
データマートとの関係性
ご紹介したようなデータレイクとデータウェアハウスとは違った特徴を持つリポジトリとして、データマートがあります。
データマートとは、利用目的などをさらに細かく設定し、データウェアハウスから必要なデータだけを抽出・加工したデータベースのことです。
データマートは、データウェアハウス以上に目的や用途を絞ってデータを抽出・加工しているため、誰でも簡単に目的に応じた情報を選別でき、素早い集計が可能となります。より多くの方がデータ活用を行うことが想定される企業では、データマートの構築も重要になるでしょう。
GCPを活用したデータレイク、データウェアハウスの構築方法
以下では、データレイク・データウェアハウスについて3大クラウドの1つであるGCPを活用した構築方法をご紹介します。
データレイクの構築方法
GCPにてデータレイクを構築する際には、オブジェクトストレージである「Cloud Storage」が適しています。Cloud Storageは大量のオブジェクト処理に適しており、詳細なアクセス制御によりデータの破損・損失に対し非常に高い耐久性を誇ります。
Cloud Storageへのデータ取込については、「Pub/Sub」と呼ばれる非同期メッセージサービスと、「Dataflow」と呼ばれるデータ処理サービスを活用します。これにより、Cloud Storageにリアルタイムのデータをセキュアに送信・保存でき、データ量に応じた入出力の調節も可能です。
データウェアハウスの構築方法
GCPでは、フルマネージドタイプのデータウェアハウス「BigQuery」が提供されています。BigQueryは、ローデータを構造化・分析するデータ分析特化型のサービスです。
BigQueryは、ツリーアーキテクチャという仕組みにて分散処理を行うことができ、大量のデータを高速で処理可能です。これにより、従来のデータウェアハウスと比べデータ分析に伴うコストの大幅な削減を実現しています。
このように、GCPを活用することでデータレイク、データウェアハウスの構築・導入を行うことができますが、GCPによる構築を行う場合、旧システムから新システムへの移行などを行う必要があるため、自社だけで行うには難しいケースも多くあります。そのため、高度な知見を持つ専門のシステムインテグレーターに外注することがおすすめです。

5つの特長やAWS・Azureとの違いなどを解説!
ビッグデータ活用に向けた基盤の構築はSproutlyにご相談ください
Sproutlyでは、データ活用に不可欠な基盤の構築をサポートしています。
今回ご紹介したGCPでの構築のほか、AWS、Azureなどメジャーなクラウド環境の構築実績が多数あり、複数のクラウド環境の結合やオンプレミスとの専用線接続といったネットワークについてトータルで設計・構築が可能です。
また、インフラからアプリケーションまで全レイヤを自社エンジニアが担当し、ワンストップでのシステム構築を実施できます。
データレイクやデータウェアハウスなどデータ基盤についてご相談の方は、以下からお問い合わせください。
このコラムを書いたライター
